A full account of building a physics-grounded RL training pipeline for datacenter operations — from custom environment to teacher-distilled SFT to live-simulation GRPO — on a single AMD Instinct MI300X.
Final Model: Melikshah/dc_ops_grpo_lora | Teacher Dataset: Melikshah/dc-ops-sft-data | Environment (HF Spaces): Melikshah/dc_ops_env | Environment Repo: TheDeadcoder/dc_ops_environment

ROCm 7.2 · PyTorch 2.10 · vLLM 0.19.1 · Unsloth 2026.4.4 · TRL 0.21.0 · HuggingFace Transformers 4.54.1
- Teaching a 7B Model to Run a Datacenter
- The Stack
- Table of Contents
- 1. Why This Problem Matters
- 2. The Environment: DC-Ops
- 3. The Training Pipeline
- 4. The GRPO Reward System
- 5. Training Results
- 6. Evaluation: Base vs. GRPO
- 7. The ROCm Engineering Story
- 8. Using the Model and Dataset
- 9. Repository Layout and Usage
- 10. Honest Limitations and What Comes Next
- Credits
Datacenters are the physical substrate of modern AI. Every GPU cluster, every inference API, every cloud storage service runs inside a facility that a small team of engineers keeps alive around the clock. Those engineers — called NOC operators — spend their shifts watching dashboards, interpreting alerts, and issuing commands to cooling units, power distribution systems, and UPS banks. When something goes wrong at 3 AM, the speed and correctness of their response is the difference between a footnote in a post-mortem and a multi-million-dollar outage.
The question I wanted to answer is simple: can a language model learn to do that job? Not simulate it loosely, but actually reason about live thermal and power dynamics, issue the right commands in the right order, and recover a failing datacenter facility from a multi-fault cascade?
The challenge is that this is not a text-matching problem. There is no "correct answer" to retrieve. The physics of a cooling system do not care about fluent prose. A model that hallucinates a plausible-sounding command — diagnosing a power distribution unit when a CRAC compressor just failed — loses time while the inlet temperature climbs past the ASHRAE allowable limit. The environment needs to be real enough that the model cannot game it.
That constraint forced me to build the training pipeline from scratch, starting with the environment itself.
DC-Ops is a physics-based datacenter operations environment I built on Meta's OpenEnv framework. It simulates a complete facility in real time: RC thermal networks for each cooling zone, UPS charge-discharge dynamics, diesel generator startup sequences, and automatic transfer switch behavior. The agent reads a text-rendered NOC dashboard and issues natural-language commands — exactly as a human operator would.
The environment is fully open-source and deployed on HuggingFace Spaces at Melikshah/dc_ops_env. It includes a web interface for interactive browsing, a full OpenAPI schema, and native TRL/GRPO integration through the OpenEnv environment_factory pattern.
I designed six operational scenarios across three difficulty tiers, covering both thermal and power fault categories:
| ID | Scenario | Difficulty | Type | Fault |
|---|---|---|---|---|
| A1 | Cooling Setpoint Optimization | Easy | Thermal | CRACs at 15°C (wasteful overcooling) |
| A2 | Thermal Event Response | Medium | Thermal | CRAC-3 compressor failure |
| A4 | CRAC Failure Cascade | Hard | Thermal | CRAC-1 compressor + CRAC-3 fan |
| B1 | UPS Alarm Response | Medium | Power | UPS transferred to battery |
| B3 | Generator Test Protocol | Easy | Power | None (routine monthly test) |
| B4 | Power Failure Cascade | Hard | Power | Utility loss + extended generator warmup |
The hard scenarios — A4 and B4 — are where the training story gets interesting. A4 presents a simultaneous failure of two CRAC units, leaving only CRAC-2 and CRAC-4 operational. The correct response is to diagnose the failed units, then redirect cooling through the survivors by raising fan speeds and carefully adjusting setpoints to compensate for the reduced capacity. B4 starts with a complete utility power loss and requires the agent to start the diesel generator, manage UPS discharge while the generator warms up, and shed rack load to extend battery life — all within a strict time budget.
The agent's observation at each step is a text-rendered monitoring dashboard, structured exactly like a real NOC screen. It shows zone temperatures, CRAC unit status, UPS state of charge, generator state, and an active alert message. The available commands are listed in the observation, and the number of steps remaining in the episode budget is shown explicitly so the agent can time its actions.
The full command vocabulary covers every action a real datacenter operator might take during an incident:
| Command | Format | Effect |
|---|---|---|
diagnose |
diagnose <unit_id> |
Inspect a CRAC, UPS, or PDU for fault details |
adjust_setpoint |
adjust_setpoint <crac_id> <temp_c> |
Change CRAC supply air temperature |
set_fan_speed |
set_fan_speed <crac_id> <pct> |
Set CRAC fan speed (0–100%) |
set_rack_load |
set_rack_load <rack_id> <kw> |
Shed or restore workload on a rack |
start_crac / stop_crac |
start_crac <crac_id> |
Start or standby a CRAC unit |
start_generator / stop_generator |
— | Manually start or initiate generator cooldown |
set_ups_mode |
set_ups_mode <ups_id> <mode> |
Switch UPS mode (eco/double_conversion/bypass) |
refuel_generator |
refuel_generator [liters] |
Refuel the diesel tank |
acknowledge_alarm |
— | Acknowledge the current active alert |
check_status |
— | Request a full status report |
escalate |
— | Escalate to a senior engineer |
wait |
— | Take no action this step |
This vocabulary is intentionally expressive. The model has to learn not just that CRAC-3 failed, but that set_fan_speed CRAC-2 100 is a better follow-up than adjust_setpoint CRAC-3 18 when CRAC-3's compressor is offline.
The environment's internal reward function is a six-component composite informed by research in datacenter reinforcement learning, including work from Google DeepMind's DC cooling experiments and the DCRL-Green paper from ICLR 2025.
Each component is normalized to [-1, 1] via tanh, and the weighted total is clamped to [-1, 1]. The weight profile switches based on scenario type — thermal scenarios weight thermal safety at 0.30 and procedure at 0.20; power scenarios flip those priorities.
Thermal Safety uses dual softplus barrier functions: a gentle penalty at the ASHRAE recommended limit and a steep penalty at the allowable limit. Softplus was chosen over hard thresholds because it provides a gradient everywhere, not just at constraint boundaries. When all zones are more than 3°C below the recommended maximum, the component returns a small positive baseline of +0.1 — a design choice from DCRL-Green that gives the agent a learning signal for maintaining good state, not only for recovering from violations.
Power Safety penalizes UPS battery depletion using a softplus barrier below 50% state of charge, and applies a fixed −5.0 penalty for any UPS entering fault mode. The penalty compounds across multiple failing units.
Efficiency uses Power Usage Effectiveness (PUE) as a continuous proxy for energy waste. A PUE of 1.0 (ideal) returns 0, PUE 2.0 returns −0.46, PUE 3.0 returns −0.76, via tanh((PUE − 1) / 2). Critically, the efficiency signal is suppressed entirely when the UPS is on battery — the agent should not be penalized for load shedding that increases PUE but correctly preserves battery runtime.
Scenario Progress uses a delta-based design: the reward is the change in progress fraction this step, not the absolute fraction. This provides credit assignment to the specific action that caused forward movement rather than distributing it across idle steps.
Procedure encodes scenario-specific procedural rules. For B4, for example, correctly starting the generator before the UPS depletes below a threshold counts as a positive procedure event.
Action Quality assesses command validity, penalizes exact repetition of non-whitelisted commands (with wait and check_status exempt), and gives a small bonus to diagnostic and investigative actions.
The pipeline has three sequential phases. Each phase feeds into the next, and each was designed to solve a specific problem that the previous phase could not.
DeepSeek-R1-Distill-Qwen-32B → SFT on Qwen2.5-7B → GRPO with live sim
(Teacher) (Student) (RL polish)
Phase 1: Data Generation Phase 2: SFT Phase 3: GRPO
The first problem I had to solve was where the training data comes from. There are no human expert trajectories for this environment. Writing them by hand would be slow, biased by my own intuitions, and would likely miss the diversity of starting conditions needed for generalization.
My solution was to use a reasoning model as a teacher: DeepSeek-R1-Distill-Qwen-32B, served via vLLM with a 24,576-token context window. The teacher runs live episodes inside the DC-Ops environment and narrates its decisions in a three-block format:
<think>
[Chain of thought — free exploration, self-correction, uncertainty.
The model thinks in its native pretraining format here.]
</think>
<reasoning>
[Distilled conclusion — ≤200 words, structured, no self-correction.
This is the canonical signal saved to the training data.]
</reasoning>
<command>
diagnose CRAC-3
</command>
I chose this three-block format deliberately. The <think> block captures the teacher's genuine reasoning process, including dead ends and corrections. The <reasoning> block is the distilled conclusion — what a skilled operator would write in a post-incident report. The <command> block is the actionable output. Saving all three means the student model has access to both the exploratory reasoning style and the clean summary.
The generation plan targeted 1,520 episode attempts across six scenarios and four variant types (standby CRAC insertion, maintenance mode, low fuel, and UPS mode switching), with seed variation for each. I ran 28 concurrent requests against the vLLM endpoint — the maximum the 192 GB MI300X could sustain without KV cache preemption at the 24,576-token context limit.
One subtle engineering decision: I strip the teacher's <think> blocks from the conversation history before feeding it back as context for the next turn. The teacher does not need to re-read its own prior chain-of-thought to pick the next action — the <reasoning> summary is sufficient. This keeps each request's input budget well under the model-context limit even on 12-turn episodes, where the growing conversation would otherwise overflow.
After filtering for episodes with at least one valid agent turn and a parseable <reasoning> block, the final dataset contained 934 kept episodes and 7,107 GPT turns. The p99 sequence length was approximately 2,700 tokens, which informed the max_seq_length: 3072 I set in all downstream configs.
| Scenario | Episodes | Share |
|---|---|---|
| A1 | 145 | 15.5% |
| A2 | 225 | 24.1% |
| A4 | 181 | 19.4% |
| B1 | 120 | 12.8% |
| B3 | 160 | 17.1% |
| B4 | 103 | 11.0% |
The dataset is published at Melikshah/dc-ops-sft-data. Each row is a ShareGPT-style episode: a conversations list of {from, value} turns covering system, human, and gpt roles. The gpt turns contain the full three-block teacher output (<think>/<reasoning>/<command>), so downstream consumers can strip <think> or keep it depending on whether their student is a reasoning or non-reasoning model.
from datasets import load_dataset
# Load the raw teacher episodes (ShareGPT-style conversations)
ds = load_dataset(
"json",
data_files={"train": "hf://datasets/Melikshah/dc-ops-sft-data/train.jsonl"},
split="train",
)
print(f"Total episodes: {len(ds)}") # 1,083 raw episodes
# Inspect a single episode
episode = ds[0]
for turn in episode["conversations"]:
role = turn["from"]
preview = turn["value"][:120].replace("\n", " ")
print(f"[{role}] {preview}...")The src/data_utils.py pipeline handles filtering (drops VAR_* variant episodes not matching the six registered scenarios), strips <think> from all assistant turns, rewrites the system prompt from the three-block to two-block format, and windows each episode into (system, [prior context], user, assistant) tuples ready for chat-template encoding. Running that pipeline on the raw 1,083 episodes yields the 934 kept episodes and 7,107 windowed training turns used in SFT.
With the teacher dataset in hand, I fine-tuned Qwen2.5-7B-Instruct using QLoRA via Unsloth. The base model is a non-reasoning model — it does not natively produce <think> blocks — so the first task was to adapt the training data and system prompt accordingly.
I wrote a rewrite_system_prompt function that collapses the teacher's three-block instruction into a two-block instruction for the student. The rewriter edits four places in the original prompt: the header changes from "Produce three blocks" to "Produce two blocks," the <think> block description is deleted, the subsequent block numbers are renumbered, and the reasoning-block copy is edited to remove its reference to <think>. Any stray <think>/</think> tokens that survive are nuked. The result is a byte-identical prompt string between SFT and GRPO, so the model sees no distribution shift at RL time.
The training data is processed the same way: <think> blocks are stripped from all assistant turns before the chat template is applied. The student learns to produce the <reasoning>/<command> two-block format without ever seeing the teacher's private scratchpad.
SFT hyperparameters:
| Setting | Value |
|---|---|
| Base model | unsloth/Qwen2.5-7B-Instruct |
| LoRA rank | 16 |
| LoRA alpha | 32 |
| Target modules | q, k, v, o, gate, up, down projections |
| Learning rate | 7e-5 |
| LR scheduler | Cosine |
| Warmup steps | 10 |
| Batch size | 10 (per device) |
| Gradient accumulation | 2 |
| Epochs | 2 |
| Max seq length | 3,072 |
| Quantization | 4-bit NF4 |
| Precision | bfloat16 |
| Gradient checkpointing | Unsloth mode |
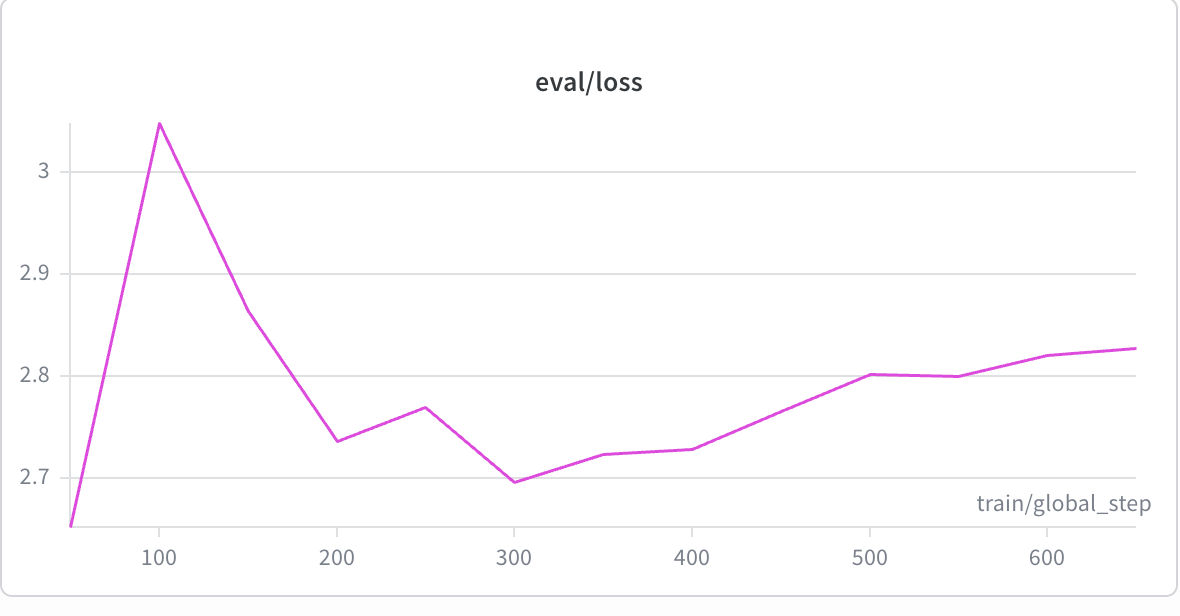
I stopped at 2 epochs deliberately. The best evaluation checkpoint was saved at eval loss 2.652 (via load_best_model_at_end: true). Beyond epoch 1.5 the loss rose consistently, and extended runs to epoch 4 produced measurably worse checkpoints (eval loss 2.827). Since GRPO provides further refinement, early SFT stopping is the correct choice.
| SFT Evaluation Loss | SFT Train Loss |
 |
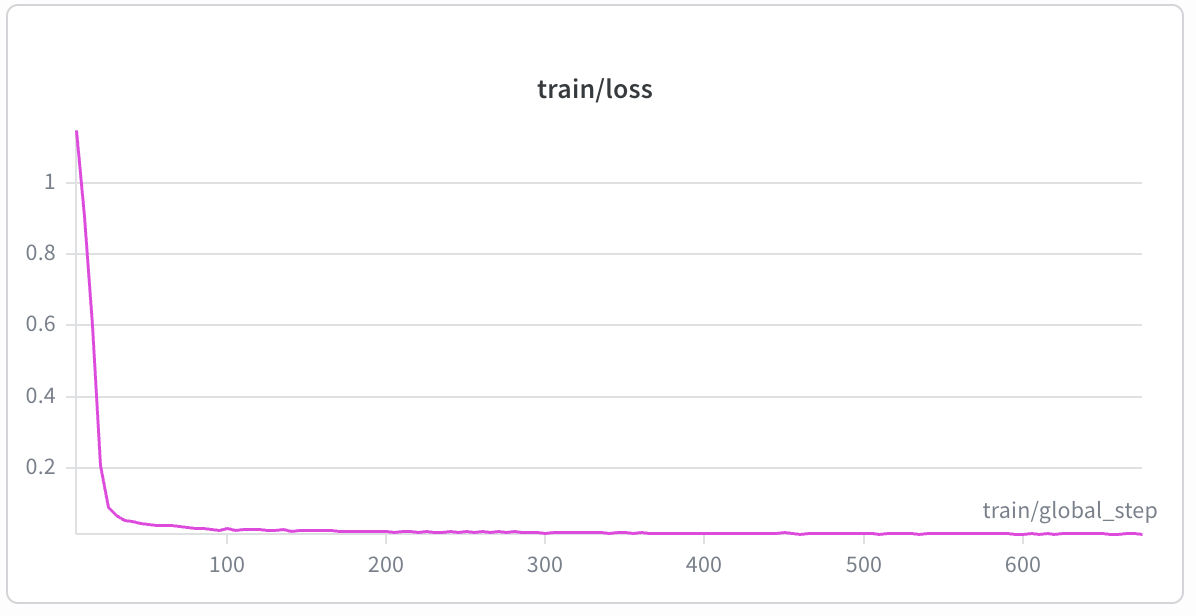 |
SFT training took approximately 60 minutes on the AMD MI300X, completing 2 epochs over 934 episodes. Train loss converged to 0.0447. Best eval loss checkpoint saved at 2.652; beyond epoch 1.5 the loss rose consistently, confirming the early-stop decision.
The SFT LoRA adapter is published at Melikshah/dc-ops-sft-lora-new and serves as the initialization point for GRPO.
Supervised fine-tuning gives the model the right format and a reasonable prior over actions. But SFT alone cannot teach the model to reason about physics. The teacher's demonstrations are noisy — not every episode resolves, not every command is the optimal choice — and the model has no feedback mechanism to distinguish good decisions from mediocre ones.
This is where GRPO enters. I used TRL's GRPOTrainer with Unsloth's vLLM fast-inference backend to run reinforcement learning directly against the live DC-Ops simulation.
GRPO hyperparameters:
| Setting | Value |
|---|---|
| Base checkpoint | SFT LoRA adapter |
| num_generations | 8 |
| max_prompt_length | 2,048 |
| max_completion_length | 512 |
| per_device_train_batch_size | 8 |
| gradient_accumulation_steps | 2 |
| effective batch | 16 (2 prompts × 8 completions) |
| Learning rate | 5e-6 |
| LR scheduler | Cosine |
| Warmup ratio | 0.1 |
| Beta (KL coefficient) | 0.05 |
| max_grad_norm | 0.1 |
| Epochs | 7 |
| vLLM temperature | 0.9 |
| vLLM top_p | 0.9 |
| GPU memory utilization | 65% |
| Precision | bfloat16 |
The effective batch of 16 completions per optimizer step (8 per_device × 2 grad_accum) satisfies TRL's constraint that the batch size must be divisible by num_generations. The configuration was tuned specifically for the 192 GB MI300X — I arrived at gpu_memory_utilization: 0.65 after hitting OOM with the more aggressive 0.75 I had tried initially.
The GRPO prompt dataset is not static. I built a build_grpo_prompts function that constructs each prompt by resetting the live environment and capturing the resulting dashboard observation. The dataset includes two types of prompts:
Initial-state prompts (30 per scenario, 180 total): the agent sees the environment at reset, with the initial alert message and dashboard state. These cover the first-response problem — what is the correct first action given this scenario?
Mid-game prompts (55 per scenario, 330 total): the environment is pre-rolled through a warmup action sequence before the prompt is captured. I defined 7–9 distinct warmup sequences per scenario, covering a range of partially-resolved states. For A4, for example, warmup sequences include ["diagnose CRAC-1"], ["diagnose CRAC-3"], ["diagnose CRAC-1", "set_fan_speed CRAC-2 100"], and several others. The mid-game prompts are more numerous than initial-state prompts because they expose the model to substantively different simulator states, not just noise variation around the same initial condition.
Seeds are varied across both types, making each (scenario, warmup, seed) combination a distinct slice of the state space. The total dataset contains approximately 510 prompts, shuffled before training.
The reward system for GRPO is separate from — and complementary to — the environment's internal reward function described in Section 2.3. It consists of four functions that together provide a dense, multi-objective signal at every training step.
This function checks for the presence and correctness of the <reasoning>...</reasoning> and <command>...</command> XML tags. It is deliberately asymmetric: well-formed output lands between [-0.2, +0.3], but malformed output is penalized heavily, down to −1.5.
The asymmetry is the key design decision. If the format reward had a flat +1.0 ceiling, the SFT checkpoint — which already emits clean format — would cause every completion in a group to score the maximum format reward. The group-mean advantage would collapse to zero, and GRPO would receive no format gradient at all. By capping the positive reward at +0.3, I ensured that small within-group variation in reasoning quality (length, domain vocabulary) still produces nonzero advantages. As it turned out, the SFT checkpoint was good enough that format compliance saturated from the very first step — which is exactly what the asymmetric design was built to handle gracefully.
Additional format signals: a deduction for <think> tags appearing in the output (the student should not be generating these), a deduction for unknown command verbs, a deduction for significant text after the closing </command> tag, and a length sweet-spot bonus (+0.15) when the reasoning block is between 25 and 180 words.
This is the richest and most expensive signal. For each completion, I spin up a fresh DcOpsEnvironment, replay the warmup actions to reach the correct mid-game state, execute the proposed command, and measure the result. The reward composition is:
r_now × 3.0 # environment's own immediate reward
+ (proxy_after - proxy_before) × 2.5 # thermal/power health delta from this action
+ (best_proxy - proxy_before) × 1.0 # stability over a 4-step wait probe
+ 3.0 if scenario resolved
- 3.0 if scenario crashed
The proxy_health score is a continuous [0, 1] metric I designed to replace the binary scenario.resolved gate. The resolved/crashed events are sparse — they happen only at episode termination — and training only on those signals would produce a reward function that is zero for most of the episode. The proxy blends two halves: the thermal half averages ASHRAE compliance scores across all cooling zones (full score at or below the recommended limit, linearly degraded through the allowable range), and the power half averages UPS battery state of charge combined with generator readiness during a utility outage. The resulting proxy is earnable in one to five steps, giving the model a dense learning signal at every training step without requiring full scenario resolution.
The 4-step wait probe after the main action is a forward stability check: I let the simulation run for four more wait steps and track whether the health score improves or degrades. An action that sets a good thermal trajectory scores higher than one that achieves the same immediate health delta but destabilizes the system.
This function encodes per-scenario prior knowledge about what constitutes a good action, without requiring a live simulation call. It is lightweight (under 1 ms per call) and provides dense per-step feedback on action alignment.
The function distinguishes two game phases: initial turns (no warmup) and mid-game turns (warmup actions already taken). For initial turns, I defined optimal, good, and bad first actions for each scenario. For A4, for example, diagnose is optimal, check_status is good, and escalate is bad. For mid-game turns, the function rewards post-diagnosis actions — set_fan_speed, adjust_setpoint, set_rack_load — and applies additional per-verb and per-target alignment checks.
The per-scenario alignment logic is specific: for A4, operating CRAC-2 or CRAC-4 (the surviving units) is rewarded, while issuing commands to the failed CRAC-1 or CRAC-3 is penalized. Setting a temperature setpoint below 17°C is penalized as harmful overcooling. For B4, starting the generator before it has been started is rewarded, while wait without the generator already running is penalized. For B1, diagnosing a UPS is optimal, and acknowledge_alarm is rewarded only after a prior diagnosis.
A small domain vocabulary bonus (up to +0.15) rewards reasoning blocks that use relevant terminology — "ASHRAE," "compressor," "setpoint," "battery SOC," and so on.
This function prevents the model from getting stuck in action loops. It tracks three types of repetition relative to the warmup history:
- Exact duplicate of any warmup action:
−1.0 - Same verb and target as a warmup action but different parameter value:
−0.4 - Redundant
waitwhen the warmup already contains await:−0.2
The wait and check_status commands are partially whitelisted because they are legitimately repeatable in some contexts. The function eliminates the behavior where the model, faced with a difficult scenario, settles into a [wait, wait, wait, ...] loop to avoid the complexity of making a real decision.
The GRPO run trained for 7 epochs (~1,784 global steps) over 4.06 hours, processing approximately 15.9 billion tokens. All results are logged to Weights & Biases under the project dc-ops-amd.
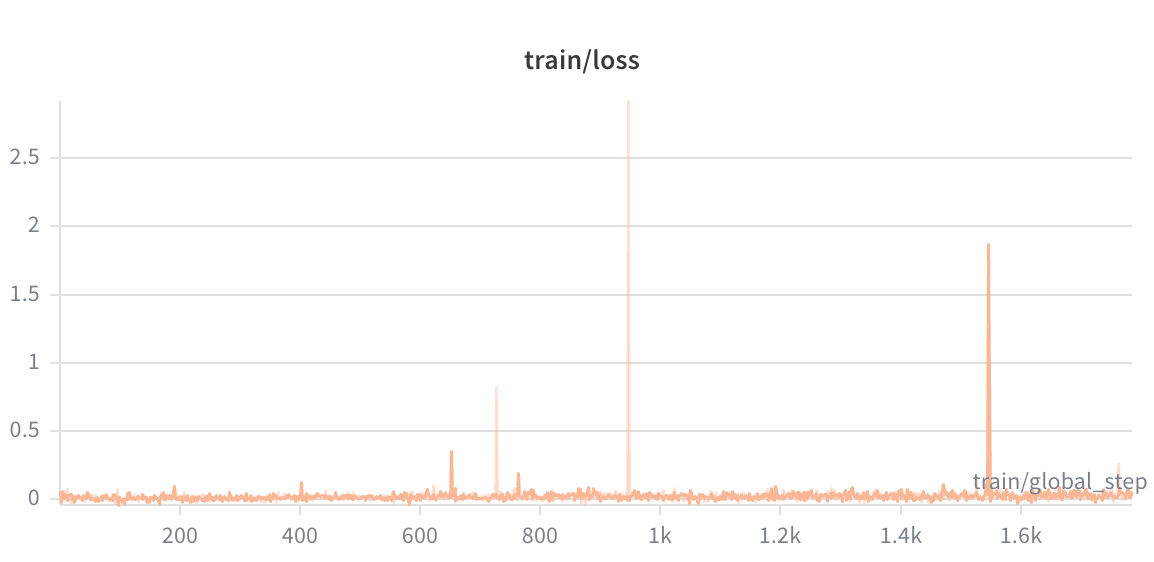
The headline result: the composite reward grew from 0.394 at the first step to 1.136 at the final step — a +188% absolute improvement. The run peaked at a composite reward of 4.130 around global step 7,500.
| Training Phase | Mean Reward | Peak Reward |
|---|---|---|
| Very first step | 0.394 | — |
| Q1 (steps 143–4,031) | 1.327 | 2.500 |
| Q2 (steps 4,031–7,559) | 1.377 | 4.130 |
| Q3 (steps 7,559–11,501) | 1.414 | 2.874 |
| Q4 (steps 11,501–15,884) | 1.183 | 2.520 |
| Very last step | 1.136 | — |
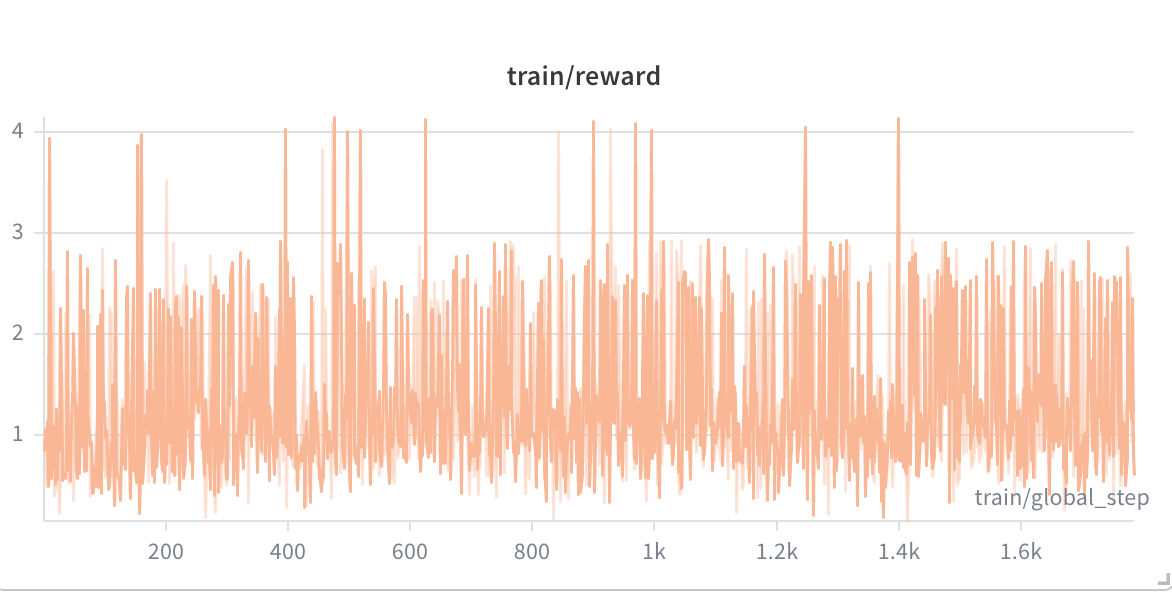
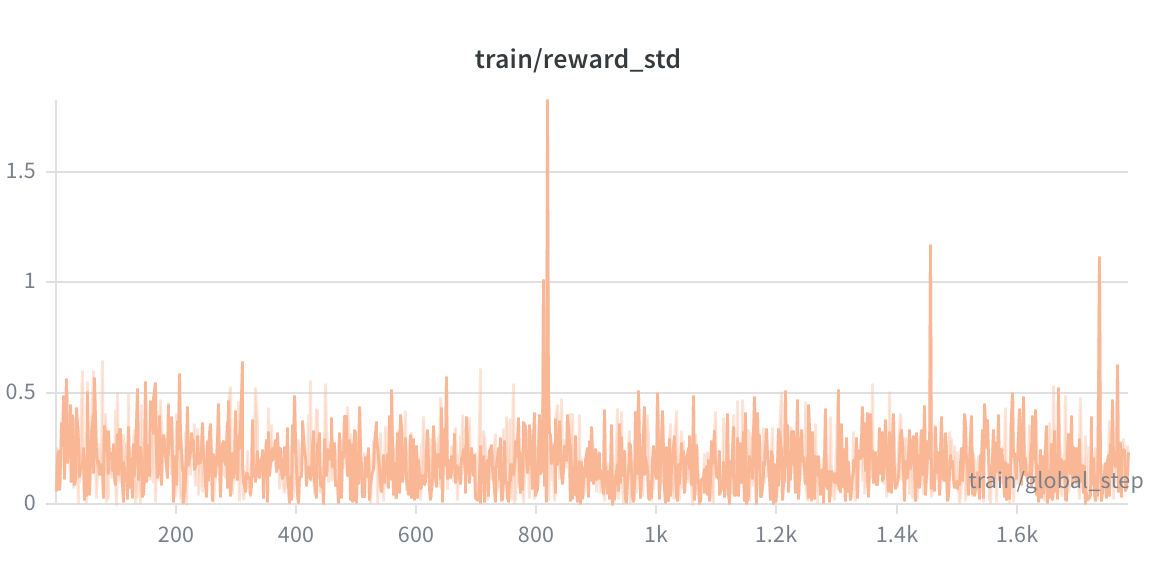
| Reward Function | Range | Run Mean | Trajectory | Signal |
|---|---|---|---|---|
format_reward_fn |
[-1.5, +0.3] |
+0.150 | 0.15 → 0.15 | Saturated perfect from step 1 |
env_reward_fn |
[-4.0, +5.0] |
+0.541 | 0.123 → 0.298 | Positive throughout, noisy |
command_quality_fn |
[-1.5, +1.2] |
+0.653 | 0.184 → 0.688 | Strong upward trend |
no_repeat_fn |
[-1.0, 0.0] |
-0.019 | -0.063 → 0.000 | Converged fully to zero |
Format compliance saturated at +0.150 with zero standard deviation from the very first training step. This is powerful evidence that the SFT checkpoint was a strong initialization — the model had already mastered the XML-structured output format. Because of the asymmetric reward design, GRPO correctly assigned zero gradient to format and redirected all learning capacity toward semantic and physical quality.
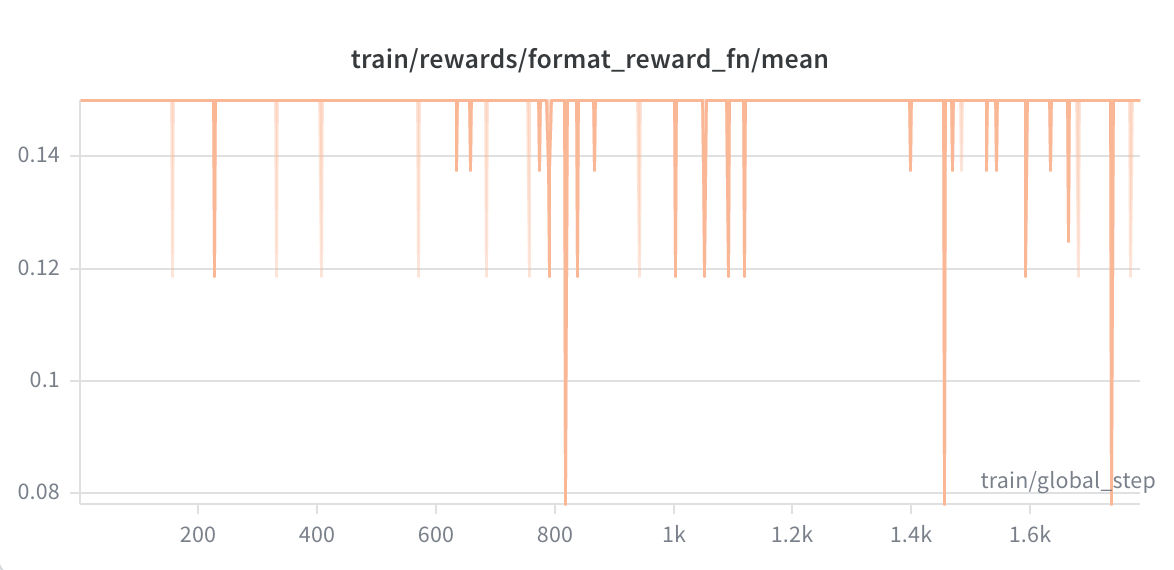
Command quality showed a steady upward trend, from a minimum of 0.184 to observed values as high as 0.947. The model progressively learned to issue diagnostically correct commands — targeting the right failing unit, using parameter ranges that the heuristics reward, and building multi-step reasoning chains that explicitly name the domain concepts the scenario requires.
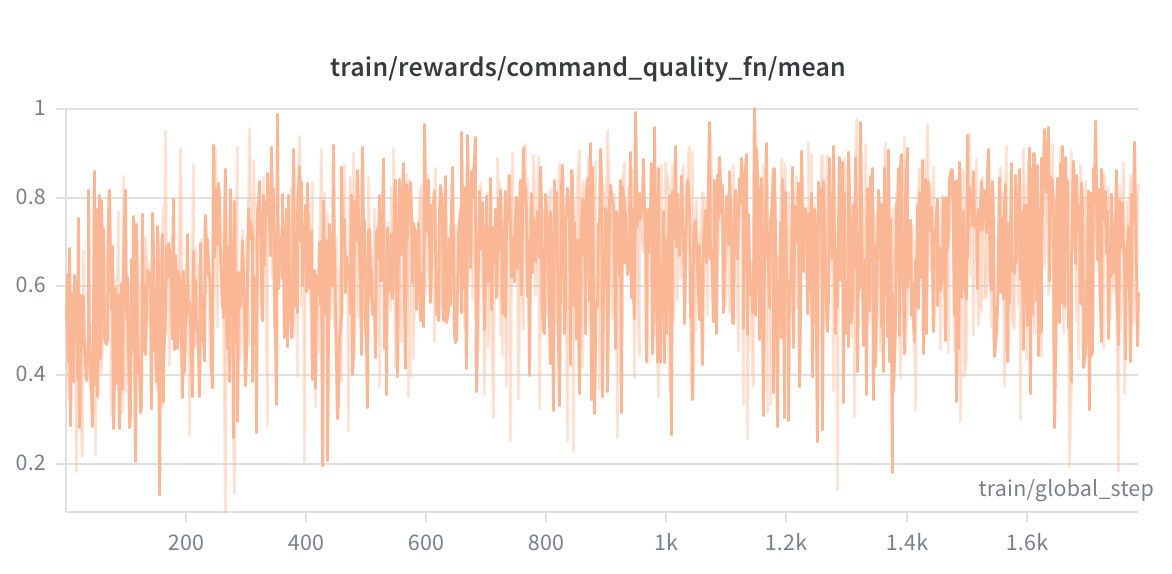
The anti-repetition penalty converged completely to zero by the end of training. The standard deviation collapsed from 0.25 to 0.00, meaning the model stopped generating repeated commands entirely. 73.8% of all records logged a no-repeat score of exactly 0.0. This is a clean behavioral convergence signal.
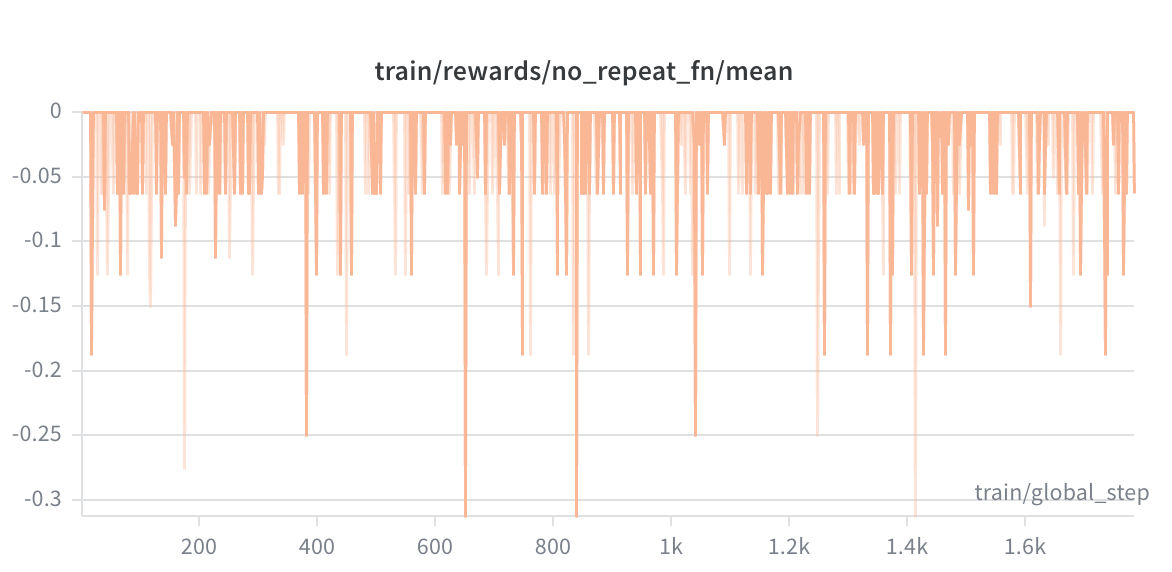
KL Divergence grew from 0.879 to 1.269 with a run-mean of 1.06. This is the expected behavior in GRPO — the policy should diverge from the frozen reference as it learns, but not so dramatically that it loses coherence. A run-mean KL of 1.06 is healthy and bounded.
Policy Loss evolved from a slightly negative value (−0.0075, consistent with a warm SFT initialization) to a small positive (0.063), indicating the GRPO gradient is actively reshaping the policy. The low magnitude throughout is characteristic of well-conditioned RL training — the model is learning without taking large gradient steps that could destabilize.
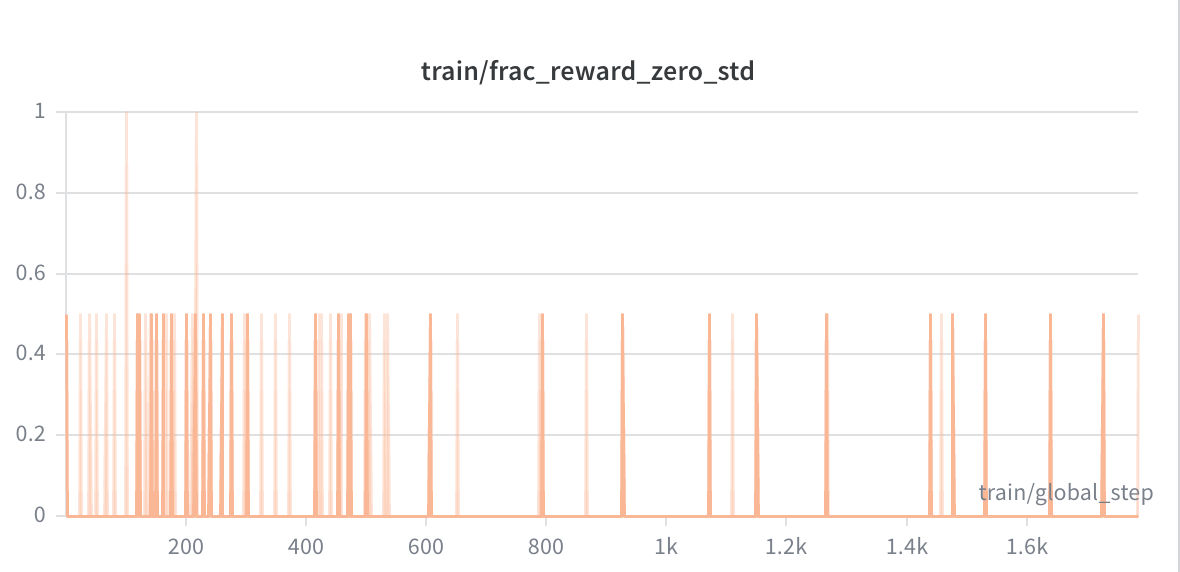
frac_reward_zero_std — the fraction of groups where all completions received identical rewards (the failure mode of GRPO, where advantages collapse to zero) — averaged only 0.033 across the entire run. In 96.7% of training groups, the model generated sufficiently diverse outputs that useful advantage estimates were available. GRPO was genuinely learning throughout.
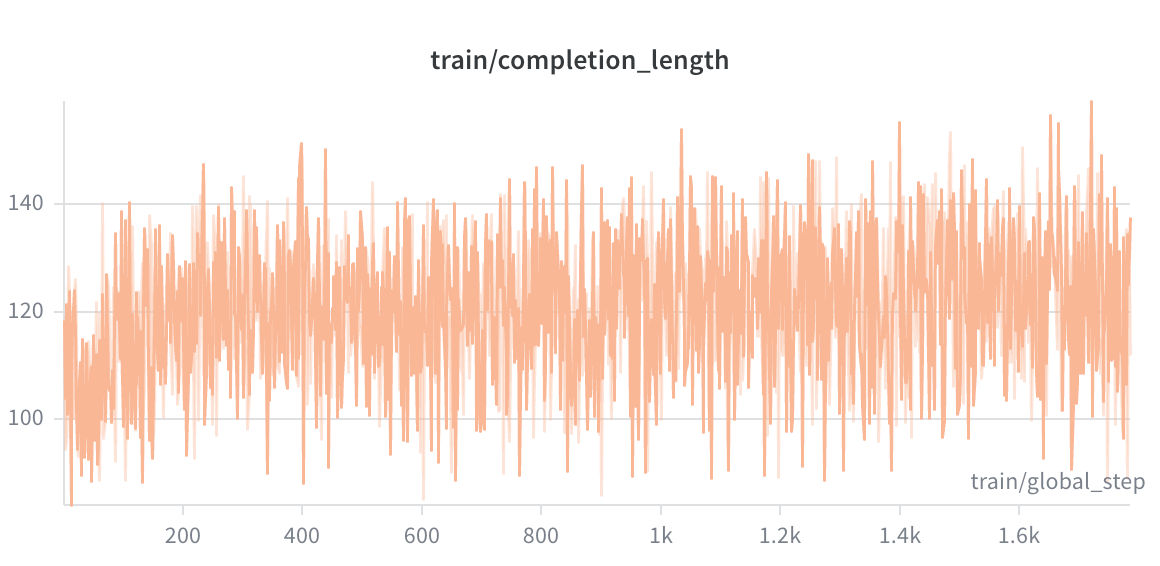
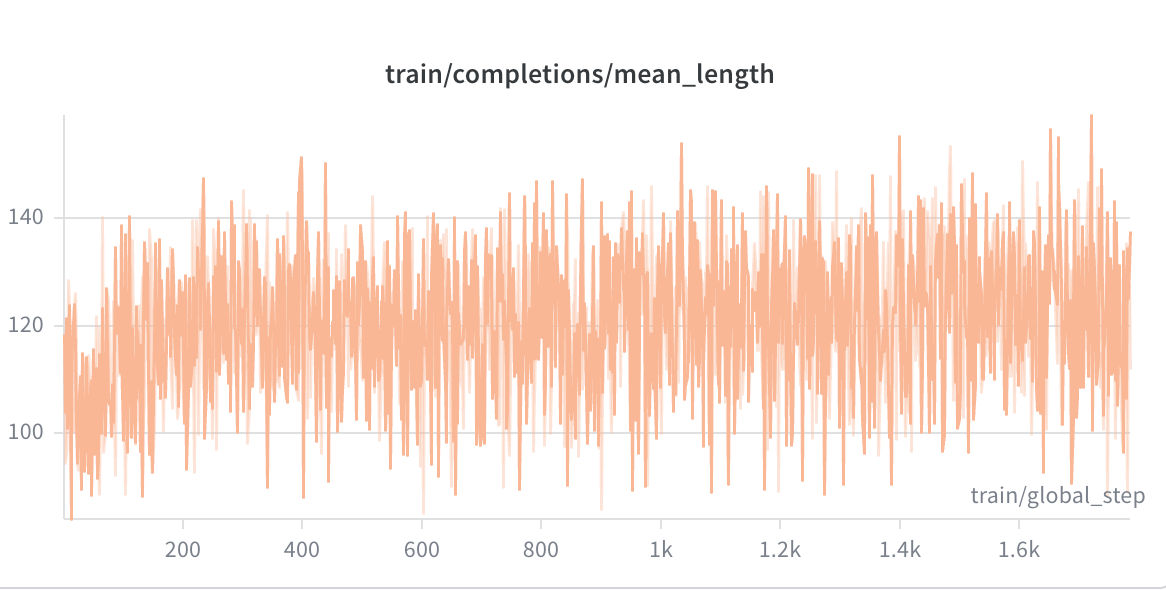
Completion Length grew from a mean of 100.3 tokens at the start to 114.4 tokens by the end — a 14.1% increase. The clipped ratio was 0.000 throughout, meaning the model never hit the generation length cap. The growing length is consistent with the model learning to use the <reasoning> block more fully to plan multi-step actions.
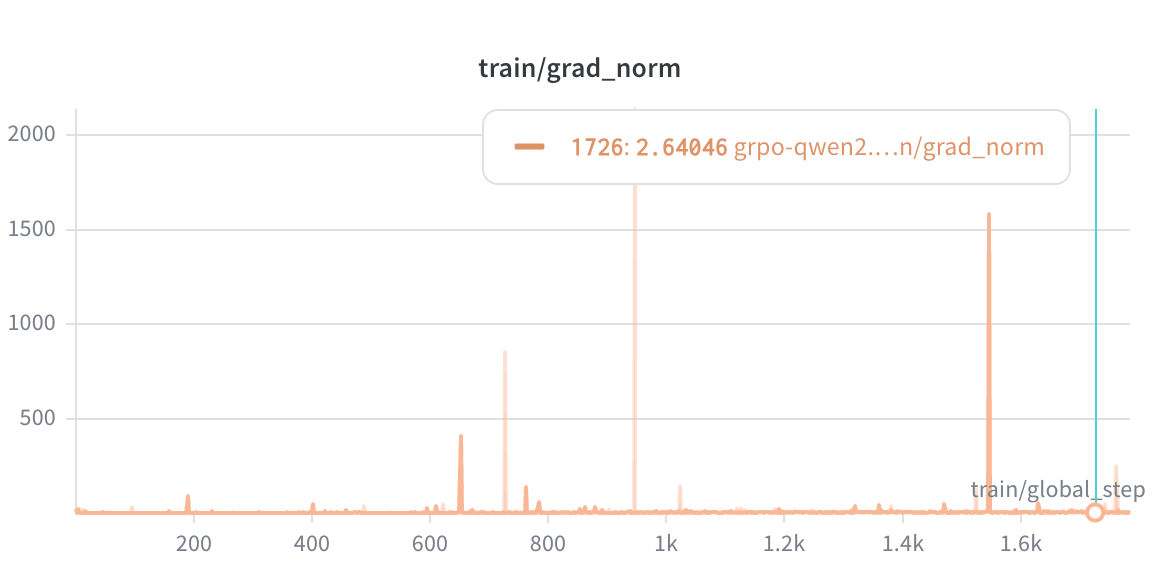
Gradient Norms showed 17 spikes exceeding 50 across the entire run (max single-step norm: 408.86), all coinciding with large-reward discovery events. The max_grad_norm: 0.1 clip and the natural LR decay prevented any of these from destabilizing training. The mean gradient norm grew from 1.95 in Q1 to 5.66 in Q4, which is expected as the policy finds steeper reward gradients.
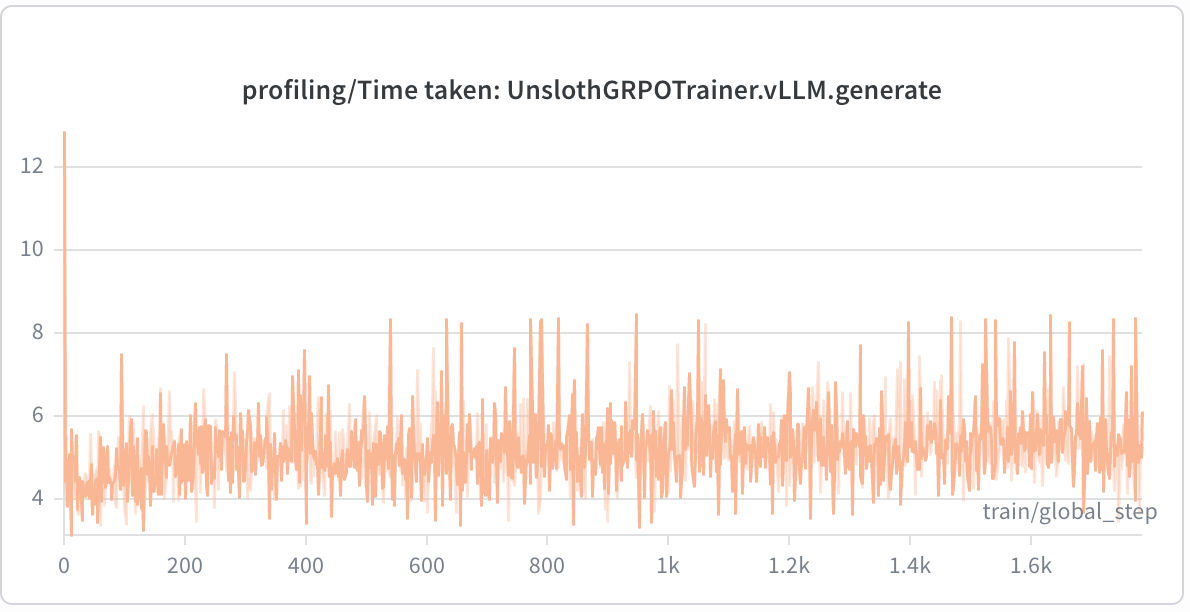
| Component | Mean Time | Max Time |
|---|---|---|
vLLM.generate |
5.18s | 8.43s |
_prepare_inputs |
3.66s | 10.13s |
_calculate_rewards |
0.68s | 0.96s |
env_reward_fn |
0.71s | 1.16s |
command_quality_fn |
0.0007s | 0.001s |
format_reward_fn |
0.0004s | 0.001s |
no_repeat_fn |
0.0001s | 0.0002s |
The training loop is compute-bound on generation (~5.2s per call) rather than reward evaluation. Even the live physics simulation adds only ~0.71s per reward call. The heuristic reward functions are negligible at under 1 ms each. This is the ideal profile for scaling: if I wanted to increase the number of generations or the environment complexity, the bottleneck remains on the GPU, not in the reward logic.
.png)
I evaluated the final GRPO checkpoint against the base unsloth/Qwen2.5-7B-Instruct model on the two hardest scenarios — A4 (CRAC Failure Cascade) and B4 (Power Failure Cascade) — across five random seeds each, with a 10-step episode budget.
python scripts/evaluate.py \
--grpo-model ./outputs/dc_ops_grpo_final \
--base-model unsloth/Qwen2.5-7B-Instruct \
--scenarios A4 B4 \
--seeds 100 200 300 400 500 \
--temperature 0.4Aggregate Results:
| Model | Scenario | N | ResRate | MeanRew | StdRew | PerStep |
|---|---|---|---|---|---|---|
| base | A4 | 5 | 0.0% | 0.041 | 0.037 | 0.004 |
| base | B4 | 5 | 0.0% | -0.147 | 0.011 | -0.015 |
| grpo | A4 | 5 | 0.0% | 0.430 | 0.033 | 0.043 |
| grpo | B4 | 5 | 0.0% | -0.092 | 0.364 | -0.009 |
On Scenario A4, the behavioral difference is stark. The base model spent most of every episode issuing wait commands, with occasional off-target actions like diagnose PDU-A-01 — completely wrong for a CRAC failure cascade. The GRPO model opened every single seed with diagnose CRAC-1, the correct first action, then moved into CRAC setpoint control on the surviving units. The mean reward improvement on A4 was +0.389 (from 0.041 to 0.430), consistent and low-variance across all five seeds.
Example GRPO rollout on A4 (seed 100):
diagnose CRAC-1 → adjust_setpoint CRAC-2 22.0 → adjust_setpoint CRAC-4 22.0
→ adjust_setpoint CRAC-4 22.0 → adjust_setpoint CRAC-4 22.0
→ adjust_setpoint CRAC-4 22.0 → adjust_setpoint CRAC-4 28.0
→ adjust_setpoint CRAC-2 28.0 → adjust_setpoint CRAC-4 27.1
→ adjust_setpoint CRAC-2 27.1
Example base model rollout on A4 (seed 100):
wait → wait → wait → wait → wait → wait → wait
→ diagnose PDU-A-01 → wait → wait
On Scenario B4, GRPO showed earlier response — the generator was started in all five GRPO seeds versus only one base model seed — but the follow-through was inconsistent. Some B4 rollouts used malformed rack identifiers (A-4, A-0, A-8 instead of A-01 through A-05), indicating the model has not yet fully learned the datacenter's rack naming convention under this power failure condition. The best B4 rollout (seed 400, total reward 0.540) diagnosed the generator first before starting it — the correct procedural order — and then systematically shed load across five racks.
The honest conclusion: GRPO produces meaningfully better emergency-response behavior than the base model, especially on hard thermal scenarios. On the power failure scenario, the improvement is real but incomplete. No episode resolved within the 10-step evaluation budget, so the resolution rate remained 0.0% for both models on both scenarios. GRPO improves the quality of each step without yet converting that to full recovery.
Running this pipeline on a single AMD Instinct MI300X (gfx942) required solving a set of compatibility problems that are not documented anywhere in consolidated form. I am writing this section because the solutions took significant time to find and will save the same time for anyone following a similar path.
The vLLM platform detection bug. On the ROCm 7.2 + vLLM 0.19.1 combination, vLLM's platform detection singleton initializes to UnspecifiedPlatform during the Unsloth import, before the HIP-compat resolver fires. This causes GPU memory queries and dtype checks to fail at runtime. My fix is a _fix_vllm_rocm_platform() function in scripts/run_grpo.py that replaces the singleton with a custom _MI300XPlatform subclass of RocmPlatform. The subclass overrides every known failing stub — check_if_supports_dtype, mem_get_info, get_punica_wrapper — and includes a __getattribute__ safety net that automatically falls back to CudaPlatform methods for any future unimplemented stubs. It then patches the new singleton into every module that captured current_platform via a from vllm.platforms import current_platform name binding, since that Python pattern creates an independent binding that module-level attribute replacement cannot reach.
The bitsandbytes symlink problem. The ROCm fork of bitsandbytes builds libbitsandbytes_rocm72.so on the host, but the Python loader probes for libbitsandbytes_rocm71.so because the validated torch stack is 2.10.0+rocm7.1. The fix is a one-line symlink:
ln -sf libbitsandbytes_rocm72.so libbitsandbytes_rocm71.soThe PEFT tensor-parallel sharding conflict. PEFT 0.19.x added LoRA tensor-parallel checkpoint sharding that expects newer Transformers internals than the 4.54.1 version in this stack. Since the single-GPU path does not need TP sharding, I disable the helper with a one-line monkey-patch in run_grpo.py:
peft.utils.save_and_load._maybe_shard_state_dict_for_tp = lambda *args, **kwargs: NoneThe import order constraint. The order of imports in run_grpo.py is load-bearing. src.rocm_env must run before any GPU-touching library. unsloth.PatchFastRL("GRPO", FastLanguageModel) must run before trl.GRPOTrainer is imported, because PatchFastRL patches the trainer class at import time. Violating this order silently produces a non-patched GRPOTrainer that rejects max_prompt_length as a constructor argument.
The Flash-Attention ROCm build. Building Flash-Attention from source against the ROCm CK (Composable Kernel) backend takes 40–50 minutes on a clean machine. I always run this step inside tmux because a dropped SSH session mid-build requires starting over. If the build fails, it is safe to skip: PyTorch SDPA on ROCm is a correct fallback at the cost of some throughput.
The validated software stack after all of the above:
| Package | Version |
|---|---|
| torch | 2.10.0+rocm7.1 |
| unsloth | 2026.4.4 |
| transformers | 4.54.1 |
| peft | 0.19.1 |
| trl | 0.21.0 |
| vllm | 0.19.1+rocm721 |
| flash-attn | 2.8.4 (CK ROCm) |
| triton | 3.6.0 |
| bitsandbytes | 0.43.3.dev (ROCm fork) |
The final checkpoint is published as a LoRA adapter at Melikshah/dc_ops_grpo_lora. It is a QLoRA adapter (rank 16, bfloat16) sitting on top of unsloth/Qwen2.5-7B-Instruct. Load it with Unsloth for 2x faster inference, or with standard Transformers + PEFT.
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="Melikshah/dc_ops_grpo_lora",
max_seq_length=3072,
load_in_4bit=True,
dtype=None, # auto-detect bfloat16
)
FastLanguageModel.for_inference(model)
# The model expects a system prompt + a user turn containing the NOC dashboard.
# The user turn format matches what the DC-Ops environment emits:
# **Action Result:** <feedback from last command>
# **Steps Remaining:** <N>
# <text dashboard>
system_prompt = (
"You are an expert datacenter NOC operator. "
"Produce two blocks in order: <reasoning>, <command>. "
"Each block must appear exactly once.\n\n"
"1. <reasoning>...</reasoning> — your concise analysis (≤200 words).\n"
"2. <command>...</command> — exactly one operator command."
)
user_turn = (
"**Action Result:** Episode started. ALERT: CRAC-3 compressor failure detected.\n\n"
"**Steps Remaining:** 15\n\n"
"=== NOC DASHBOARD ===\n"
"Zone A | Inlet: 27.3°C | CRAC-1: OK | CRAC-2: OK | CRAC-3: FAULT | CRAC-4: OK\n"
"Available commands: diagnose, adjust_setpoint, set_fan_speed, set_rack_load, ..."
)
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_turn},
]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
).to("cuda")
outputs = model.generate(
input_ids=inputs,
max_new_tokens=512,
temperature=0.4,
do_sample=True,
top_p=0.9,
)
response = tokenizer.decode(outputs[0][inputs.shape[1]:], skip_special_tokens=True)
print(response)
# Expected output shape:
# <reasoning>
# CRAC-3 compressor has failed. Zone A inlet is rising. I need to diagnose
# the unit to confirm the fault type, then compensate with CRAC-1 and CRAC-2.
# </reasoning>
# <command>
# diagnose CRAC-3
# </command>For a fully interactive evaluation loop against the live DC-Ops environment, use the scripts/evaluate.py script in this repository:
python scripts/evaluate.py \
--grpo-model Melikshah/dc_ops_grpo_lora \
--base-model unsloth/Qwen2.5-7B-Instruct \
--scenarios A2 A4 B4 \
--seeds 100 200 300 \
--temperature 0.4dc-ops-amd/
├── configs/
│ ├── grpo.yaml # GRPO hyperparameters and vLLM settings
│ └── sft.yaml # SFT hyperparameters and LoRA settings
├── launch/
│ ├── grpo.sh # nohup launcher: loads .env, activates venv, logs
│ └── sft.sh
├── scripts/
│ ├── run_sft.py # SFT training entry point
│ ├── run_grpo.py # GRPO training entry point (ROCm patches included)
│ ├── evaluate.py # Head-to-head evaluation script
│ ├── eda.py # Dataset analysis
│ ├── push_to_hf.py # Push LoRA adapter to HuggingFace Hub
│ └── verify_setup.py # Stack verification (run before training)
├── src/
│ ├── constants.py # Scenario IDs, known commands, per-scenario priors
│ ├── data_utils.py # Dataset loading and preprocessing
│ ├── grpo_data.py # GRPO prompt-dataset builder (live env)
│ ├── prompts.py # System prompt rewriting and observation formatting
│ ├── rewards.py # Four GRPO reward functions
│ └── rocm_env.py # ROCm environment variables (must import first)
├── server_ouputs/ # Training run logs from the actual runs
│ ├── grpo.md # Full GRPO analysis report
│ ├── eval_result.md # Base vs. GRPO evaluation
│ ├── sft.md # SFT training run log
│ └── verify.md # Stack verification output
└── setup_env.sh # Full ROCm stack installation script
Quick start:
# 1. Install environment (takes 40-50 min for ROCm flash-attention)
tmux new -s setup
./setup_env.sh
# 2. Create bitsandbytes symlink
cd .build/bitsandbytes/bitsandbytes
ln -sf libbitsandbytes_rocm72.so libbitsandbytes_rocm71.so
# 3. Configure credentials
cp .env.example .env
# Edit: HUGGINGFACE_TOKEN, WANDB_API_KEY
# 4. Verify stack
source .venv/bin/activate
python scripts/verify_setup.py
# 5. Run SFT
./launch/sft.sh && tail -f logs/sft-*.log
# 6. Run GRPO
./launch/grpo.sh && tail -f logs/grpo-*.logThe GRPO script resolves the SFT source automatically: it prefers ./outputs/dc_ops_sft_lora (local checkpoint) and falls back to configs/grpo.yaml's model.sft_model_hub when the local directory does not exist. This means the SFT and GRPO runs can be on different machines without any manual path editing.
I want to be direct about what this project has and has not achieved.
The GRPO model shows a genuine and measurable behavioral improvement over the base Qwen2.5-7B-Instruct model. On Scenario A4, the mean per-step reward improved from 0.004 to 0.043 — more than a 10x increase — with low variance across seeds. The model learned to diagnose the correct failing unit, issue commands to surviving units rather than failed ones, and avoid the passive wait loops that dominate the base model's behavior.
At the same time, neither model resolved any episode within the 10-step evaluation budget. Full scenario resolution on the hardest incidents requires a longer planning horizon than 10 steps, and possibly a larger model or more training data. The B4 power scenario remains difficult: the model knows to start the generator but struggles with the subsequent load-shedding step-sequence, including some malformed rack identifiers in the output.
The training dataset of 934 episodes is small by LLM standards. The teacher model generated good-quality trajectories, but a larger, more varied dataset — particularly with more coverage of multi-fault partial-recovery states — would likely improve both the SFT initialization and the diversity of GRPO rollouts.
There are also structural improvements I want to make to the reward system. The env_reward_fn currently runs a full environment reset and replay for each completion in a group of 8, making it the second-most expensive component in the pipeline after generation. Batching those environment steps would reduce wall-clock time significantly. The proxy health score is a reasonable approximation, but a richer simulation-driven dense reward — one that tracks not just thermal compliance but rate of change and trajectory direction — would give the model better gradient signal for multi-step planning.
Despite these limitations, the core result holds: a 7-billion-parameter model can learn to reason about real physical systems through reinforcement learning against a live simulation, without any human-labeled data, on a single consumer-class GPU. The training pipeline is fully reproducible from the code and configs in this repository.
- Environment: TheDeadcoder/dc_ops_environment
- Base Model: unsloth/Qwen2.5-7B-Instruct
- Teacher Model: DeepSeek-R1-Distill-Qwen-32B
- SFT Dataset: Melikshah/dc-ops-sft-data
- Final Model: Melikshah/dc_ops_grpo_lora
- Environment (HF Spaces): Melikshah/dc_ops_env
- Frameworks: Unsloth, TRL, OpenEnv, vLLM